Telemetry-First Sub-Agent Dispatch Saved Me 18 Minutes on a Quota Cliff

The Moment It Hit
Twenty-five agents in, the next batch came back with "session limit · resets 1:40pm Asia/Kuala_Lumpur." I closed my laptop and made coffee. Eighteen minutes later I restarted exactly four agents: the ones that had been dispatched but not confirmed complete. The telemetry was the reason.
That was the payoff for six lines of Python I had written before the first agent ever fired. The recovery was clean not because I got lucky, but because the session file already contained a record of every dispatch and every completion. Finding the gap between those two sets took about ten seconds. The retry ran exactly the cases that needed it and left everything else untouched.
The Pattern in Plain Terms
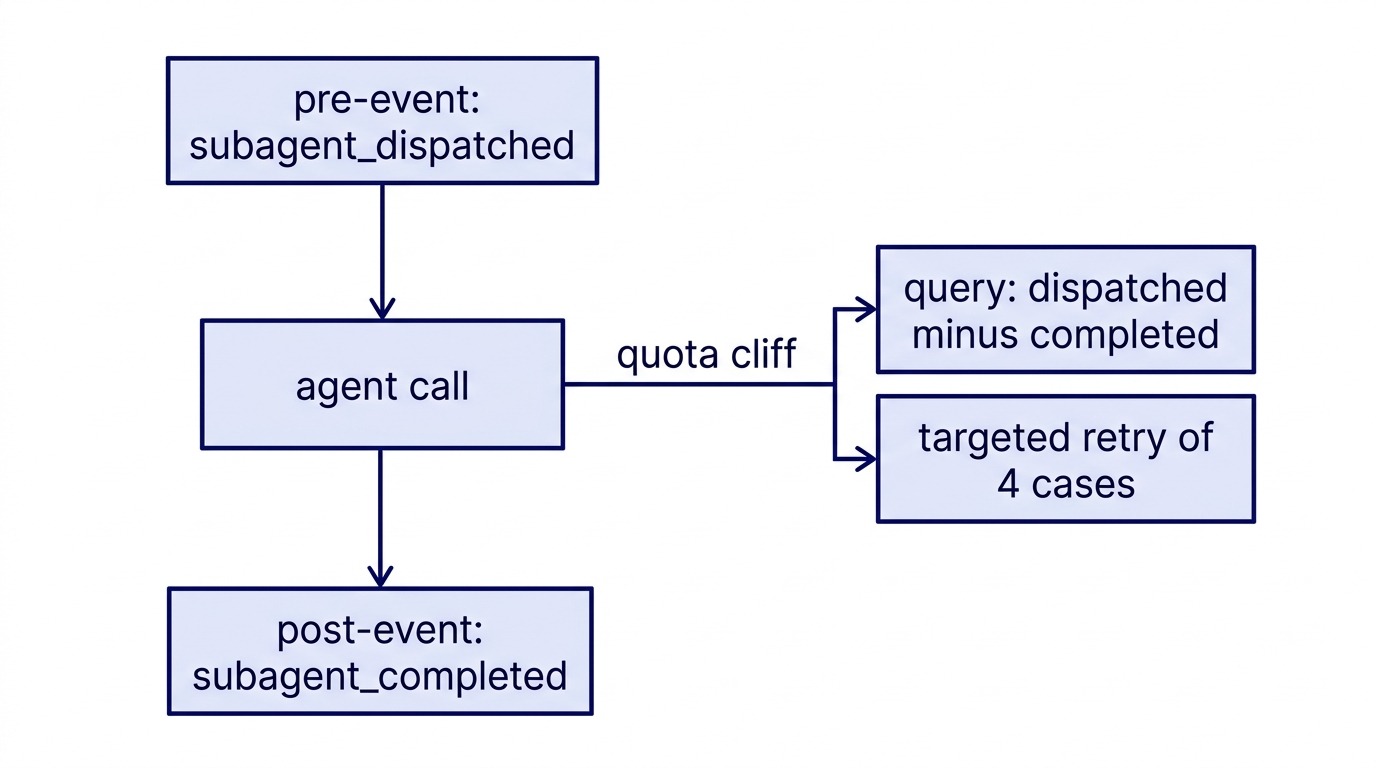
The core idea is two writes per agent call: one before the call, one after. Both land in the same JSONL file. Both carry the same chunk_id so they can be matched later.
The pre-dispatch event says: "I am about to fire an agent for this case, with this task description, in this batch." The post-completion event says: "That agent finished, with this result, writing to this file." If the session ends before the post-completion event is written, the gap is visible immediately. You do not need to diff a folder or reconstruct a timeline. The absence of the closing event is the signal.
This is how you would design an audit trail for a finance system: an event before the journal entry is posted, and a confirmation event after posting succeeds. If the system crashes between the two, the incomplete entry is trivially identifiable on recovery. The same logic applies here. Parallel sub-agent dispatch has the same failure mode as any distributed write: partial progress is the normal failure shape, and the only reliable way to detect it is to record intent before execution and outcome after.
The file format is JSONL: one JSON object per line, appended atomically with a newline terminator. Each line is independent. A partial write at the end of a file (which can happen during a hard stop) does not corrupt the preceding lines. This is the cheapest durable log format available in Python.
The Code
Here is the helper function. It stamps the event with the current time and appends it to the session file. That is the entirety of the infrastructure.
import json
from datetime import datetime
from zoneinfo import ZoneInfo
MYT = ZoneInfo("Asia/Kuala_Lumpur")
def emit_event(session_path: str, event: dict) -> None:
event["ts"] = datetime.now(MYT).isoformat()
with open(session_path, "a", encoding="utf-8", newline="\n") as f:
f.write(json.dumps(event, ensure_ascii=False) + "\n")
You call it twice per agent. Once before the dispatch, once after the result comes back (or the exception is caught).
# Before firing the agent
emit_event(session_path, {
"event": "subagent_dispatched",
"session_id": session_id,
"chunk_id": "batch-3-case-027",
"task_description": "Route prompt to expected skill",
"items_assigned": 1
})
result = run_agent(case) # your actual dispatch call here
# After the agent returns
emit_event(session_path, {
"event": "subagent_completed",
"session_id": session_id,
"chunk_id": "batch-3-case-027",
"success": result.ok,
"output_file": result.output_path
})
If the agent errors, catch the exception, set success: False, and add an error field with the message before calling emit_event. If the session hits a quota wall and the agent never returns, the subagent_completed event is simply never written. That absence is the entire recovery signal. You do not need to add any additional error-detection logic. The gap in the event stream is self-reporting.
One thing worth noting: the chunk_id is the join key. It needs to be unique per dispatched work unit and consistent between the pre and post events. I use a composite string of batch number and case identifier. Any stable, unique string works.
The Recovery
The benchmark I was running was a 50-case router accuracy test, dispatched in 5 parallel batches of 10 sub-agents each. Each sub-agent read a prompt, considered a 19.7K-token skill description block, and returned a ranked JSON response. The quota cliff arrived mid-run at 25 cumulative agents, roughly 2.1 million cumulative tokens consumed. Four of the ten agents in the affected batch returned the quota error message instead of their response JSON.
The recovery query was a single conceptual operation: find every chunk_id that has a subagent_dispatched event in the session file but no corresponding subagent_completed event.
import json
events = [json.loads(line) for line in open(session_path, encoding="utf-8")]
dispatched = {e["chunk_id"] for e in events if e["event"] == "subagent_dispatched"}
completed = {e["chunk_id"] for e in events if e["event"] == "subagent_completed"}
needs_retry = dispatched - completed
print(needs_retry)
The output was exactly four case identifiers. I restarted those four after the quota window reset. Everything else was confirmed complete and left alone.
Here is the part I found most instructive: two of those four had actually written their output JSON files before the quota error surfaced. The failure happened after the file write completed but before the subagent_completed event was emitted. My initial plan was to re-dispatch all four. But before firing them, I checked the output files for the two in question and found valid JSON in both. Their work was done. For those two, I wrote the completion events manually (marking them successful and pointing to the existing output files) and skipped re-dispatch entirely.
The telemetry did not just tell me which cases had failed. It also gave me a reason to inspect before blindly retrying. That inspection saved two redundant agent calls. In a longer benchmark, the same check would save proportionally more.
Without the event stream, the recovery options were both worse. Re-running all 50 cases would have been wasteful and would have overwritten valid output from the first run. Manually diffing the response folder against the fixture to infer which cases had completed would have been slow and unreliable, because a partial JSON write looks like a present file even though the content may be corrupt. The event stream is the cleaner path.
The Compounding Benefit
The quota recovery was the immediate reason I am glad I wrote the telemetry. But the same JSONL file remains useful weeks later.
The 50-case benchmark produced 178 structured events across the full run. Every dispatch, every completion, every failure is in the file. Retrospective questions that would otherwise require reconstructing a run from session logs are now trivial.
Total agents dispatched: count subagent_dispatched events. Success rate by batch: group by the batch prefix in chunk_id, tally success values. Which cases had no output file: join completion events against the responses folder. Cost per completed case: if you add a tokens_used field to the completion event (easy to instrument if your agent SDK returns usage data), the per-case cost aggregation is a one-liner.
This is the property that makes telemetry worth writing even when you are not anticipating failures. The observation infrastructure you build for fault recovery is the same infrastructure you use for retrospective analysis and cost accounting. You write one event stream and it answers questions from two different time horizons: the immediate "what needs retry right now" and the deferred "how did this benchmark actually perform." Building two separate systems for those two questions would cost more in total than building one structured log.
When This Pays Out Next
The pattern is worth applying to any parallel pipeline where work is expensive to repeat. Content generation batches, image generation queues, evaluation harnesses, document processing pipelines: all of them share the same shape. You fire multiple agents, some of them may fail, and you want recovery to cost proportionally to the failure rather than proportionally to the full run.
The precondition for this to work is that each work unit has a stable identifier (the chunk_id), that the output of each unit lands in a deterministic location, and that the session file is written to durable storage before the dispatch starts. All three are easy to arrange at design time and difficult to retrofit after a failure.
If you are running more than ten agents in a single session, the event writes cost almost nothing compared to the work they protect. A quota cliff, a network blip, a partial batch failure: any of these turns a guessing problem into a set subtraction. The next one will come. The question is whether your session file tells you exactly what to retry, or whether you are starting over from the top.
Part of the Operating Principles series from KG Consultancy.
Strategy and technology are the same decision. Over 15 years in fintech (CTOS, D&B), prop-tech (PropertyGuru DataSense), and digital startups, I have built frameworks that help founders and executives make both moves at once. Based in Kuala Lumpur.
Working on a 0→1 product?
I help founders and operators go from idea to validated product. Let's talk about yours.
Get in touch →