The Two-Tier Staff Agent Pattern: Strategic Ara, Operational Deeno

For months my one "AI assistant" would sometimes give me strategic reflection when I wanted a checklist, and sometimes give me a checklist when I wanted strategic reflection. The fix was not better prompting. The fix was hiring two.
The two-register problem
Every AI workflow that lasts long enough develops two jobs that look similar on the surface but are cognitively different underneath.
The first job is strategic pattern-spotting: what is true across all my client engagements this month? What am I systematically ignoring? What thread keeps appearing in different contexts? This register wants space and time. It asks questions that do not have obvious answers yet. Done well, it produces one or two genuinely surprising observations per month.
The second job is operational closure: what research recommendation did I queue three weeks ago and never action? What task is sitting in my system with no owner? What should I have done yesterday? This register wants precision and momentum. It asks questions with clear, retrievable answers. Done well, it produces a short list and a cleared inbox.
Both registers use the same model. Both can be served by the same agent in theory. But asking the wrong register the right question is worse than asking the right register the wrong question, because the wrong-register answer sounds plausible. Strategic reflection dressed up as a checklist is the worst possible output: it has the form of an action item and the substance of vague advice. Operational closure dressed up as strategic insight is equally useless: it has the form of a pattern observation and the substance of "you have 14 unread emails."
The insidious part is that both failure modes look like AI output rather than register failure. A consultant reviewing the output would say "that answer is a bit vague" or "that answer is a bit tactical." They would not say "you asked the operational register a strategic question." The register mismatch is invisible unless you have named the registers, which most people have not done because they are using one agent and calling it their assistant.
The problem is that conflating the two registers in one agent inbox produces exactly this mush, reliably and at scale.
Naming as routing
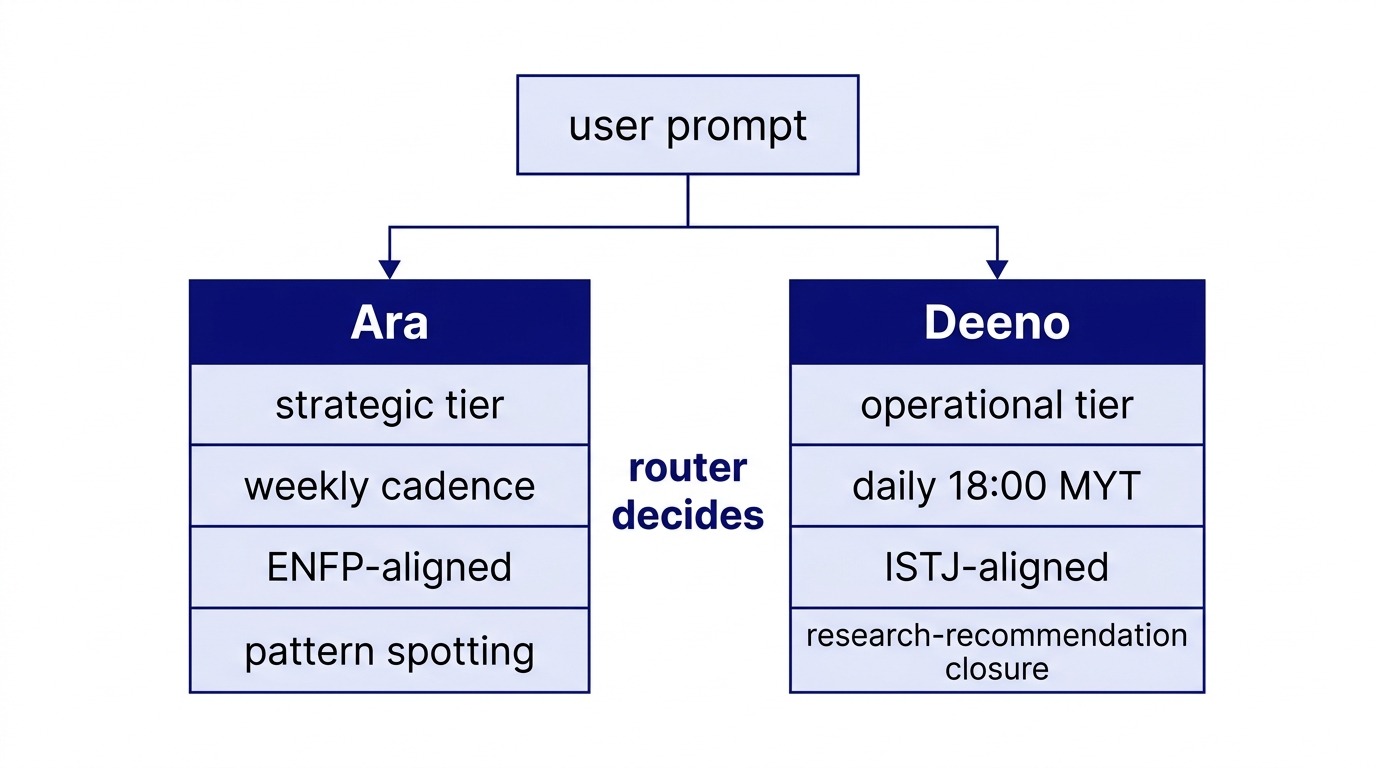
The architectural insight is simple. When you give the two registers distinct names, distinct personalities, and distinct invocation triggers, the register-switch becomes a routing decision rather than a model-output negotiation.
I built a 103-skill Claude Code corpus over the first three months of 2026. At the core of that corpus are two staff agents: Ara, the strategic-tier thinking partner, and Deeno, the operational-tier research foreman. Each is a separate skill with its own SKILL.md, its own trigger phrases, and its own NOT-clause that explicitly disclaims the other tier.
Ara's description says, in plain terms: "NOT kg-deeno's research-recommendation-tier." Deeno's description says the equivalent in reverse. The result is that the LLM router, when presented with a prompt that could plausibly go to either, has a clear signal. The descriptions tell it what each agent does not do. Disambiguation by exclusion is more reliable than disambiguation by description alone, because the failure mode (routing to the wrong agent) maps directly to the NOT-clause that should have caught it.
On a 50-case adversarial benchmark I ran against the full corpus, the two-tier agents routed cleanly. The cases that caused confusion elsewhere in the corpus were the ones with overlapping or vague scopes. Ara and Deeno had none of that confusion, because I had written the boundary explicitly into both descriptions.
The user-side benefit is just as real. When I type "Ara" at the start of a message, I am not guessing which mode the AI is in. I know. The cognitive overhead of "which register am I in right now?" disappears entirely, because I made the decision at the moment I named the agent, not at the moment I compose the query. That is 30 seconds of cognitive overhead recovered on every single message that touches either register.
The cadence as a routing signal
Ara is weekly. Deeno is daily at 18:00 MYT.
This is not incidental. The cadence enforces the register.
Strategic reflection at daily cadence becomes noise. If I am asking "what patterns am I missing across all my engagements?" every morning, the question degrades. Most days the answer is "nothing new since yesterday." The signal-to-noise ratio collapses, and strategic reflection stops feeling useful.
Operational closure at weekly cadence accumulates rot. Research recommendations that were not actioned on Monday are probably not going to be actioned on Friday either if there is no daily check. An audit I ran in April 2026 found that 26% of research recommendations I had queued through my research pipeline had rotted silently over six months, never implemented, never actively cancelled. A daily 18:00 sweep by Deeno dropped that rate to near zero within a month. Not because the agent was smarter, but because the cadence matched the register.
Time is a routing signal too. When you set the cadence of a register correctly, you are making a structural claim about how often that kind of thinking pays off. Strategic reflection pays off once per week. Operational closure pays off once per day. Setting the cadence incorrectly wastes either the strategic register's depth or the operational register's momentum.
This maps directly to how a finance function should be structured. In management accounting, strategic FP&A operates on a monthly or quarterly cadence, looking forward across the business at a planning horizon. Operational management accounting runs daily and weekly at the cost-centre level, looking at variances and ensuring the numbers are right before the month closes. Conflating the two cadences into a single reporting rhythm produces reports that are neither strategic enough to inform decisions nor granular enough to catch errors. The two-register split in AI workflow is the same principle applied to a different tool.
The MBTI question
I framed Ara as ENFP-aligned and Deeno as ISTJ-aligned. Some readers will recoil from this.
The framing is not a claim about personality science. I am not arguing that agents have personalities in the way people do, or that MBTI is a validated psychometric instrument. The framing is a routing aid.
Giving each agent an internally consistent personality shorthand lets the LLM stay in character across sessions, which keeps the register stable. An ENFP-aligned agent, in prompt terms, is one that tends toward intuition over sensing, that prioritises synthesis over enumeration, that is comfortable holding open questions. An ISTJ-aligned agent, in prompt terms, is one that tends toward closure over openness, that prioritises completion over exploration, that is uncomfortable leaving items without a clear resolution path.
Those two descriptions, in long form, would cost three paragraphs each. The MBTI labels compress them into two words. The compression is the point. When I spin up a new skill that chains to Ara, I can write "Ara-adjacent: synthesise across contexts before recommending" rather than re-writing the personality architecture from scratch. When I spin up a skill that chains to Deeno, "Deeno-adjacent: closure-oriented, triage the list, surface the overdue" is enough.
The personality framing is most useful when the corpus grows large enough that new skill authors (including future-me) need a shorthand for what each tier does. Three words beats three paragraphs every time.
Where the pattern compounded
April 2026 was the month three observations converged into the decision to split the registers.
First, I noticed I was asking the same question across different project contexts. "What am I missing this week?" was appearing in my prompts at least once per project per week. That is not casual reflection. That is real work being done ad hoc rather than systematically. Ara was built to absorb that question into a weekly Pattern Spotter cadence.
Second, the research-rot audit. The 26% figure was not a failure of the research pipeline. The pipeline was working: it queued recommendations, flagged relevance, linked to source material. The failure was that no agent had a standing brief to triage those recommendations daily and push them toward resolution or cancellation. Deeno was built for that slot.
Third, the mush problem. I could see in session after session that asking one agent for both registers produced outputs that were hard to act on. The strategic framing bled into the operational output and vice versa. The split made each tier sharper immediately, not gradually.
In structural terms, the split meant two separate SKILL.md files, two separate sets of invocation triggers, two separate NOT-clauses pointing at each other, and two separate cadences. The total additional writing was about four hours. The design work, thinking through where the boundary sits and how to describe it in a way the router can use, was another two. Six hours total for a structural change that altered the quality of every session afterwards.
After the split, each tier started producing the output it was supposed to produce. Ara's Pattern Spotter began surfacing one or two genuinely surprising cross-engagement observations per month that I would not have reached without it. Deeno's daily 18:00 sweep converted queued research recommendations into actioned or explicitly cancelled items. The 26% rot rate went to near zero.
The router benchmark result confirmed what the operational experience suggested. The two-tier agents were the cleanest routing boundary in the entire 103-skill corpus, because the NOT-clauses made the boundary legible to the router, not just to me.
The operator takeaway
If your AI workflow has two registers that share an inbox, split them.
Give each one a name. Give each one a cadence that matches the register's natural frequency. Give each one a NOT-clause that explicitly disclaims the other's scope. Write the boundary in both descriptions, not just one.
The router, whether it is a human reading their own prompt or an LLM dispatching to the right skill, will do the rest. You are not making the AI smarter by splitting the registers. You are making the routing decision earlier in the chain, where it is cheaper and more reliable.
The split is one afternoon of design work. The compound return on that investment runs every session afterwards.
If I were starting over
There is one thing I would add from day one: a third tier built for measurement.
My measurement-tier agent, kg-ce, was built in May 2026 after the strategic and operational tiers were already running. By that point, I had two agents producing output every day and every week, but no agent whose job was to evaluate whether that output was improving over time. The measurement tier had to be retrofitted.
If I were designing the system from the start, the three tiers would be: strategic (Ara, weekly pattern-spotter), operational (Deeno, daily closure engine), and measurement (one run per fortnight, evaluating whether the first two are producing the right outputs and routing correctly). The measurement tier does not need to run often. It needs to run before drift becomes invisible.
One week of invisible drift is recoverable. Three months of invisible drift is a rewrite.
Part of the Knowledge Management series from KG Consultancy.
Strategy and technology are the same decision. Over 15 years in fintech (CTOS, D&B), prop-tech (PropertyGuru DataSense), and digital startups, I have built frameworks that help founders and executives make both moves at once. Based in Kuala Lumpur.
Working on a 0→1 product?
I help founders and operators go from idea to validated product. Let's talk about yours.
Get in touch →